SierraDB: A Distributed Event Store Built in Rust
Posted October 21, 2025 by Ari Seyhun ‐ 10 min read

Introduction
Every system has a story — event sourcing makes sure you never forget it. Event sourcing is a niche, yet important pattern in software development. Despite this, there's absolutely no clear cut way of approaching it for new projects, especially when it comes to how and where events are stored. Some advise using existing general purpose databases such as Postgres, or even Kafka. However, event sourcing has specific requirements that make general-purpose databases either overkill or missing key features.
This gap in the domain of event sourcing specific databases is what led me to build SierraDB, a horizontally scalable database built from the ground up in Rust.
The Problem with Event Sourcing Databases
On the spectrum of storage solutions, purpose built event sourcing databases can be counted on one hand. These include Kurrent (formerly EventStoreDB), AxonServer, and some other solutions built on top of Postgres. However, the former two databases built from the ground up are built in garbage collected languages, which, in my view, are suboptimal for building high-performance databases.
Event sourcing demands specific guarantees that general purpose databases struggle with: truly append-only storage, gapless sequence numbers, efficient stream reading, and built-in subscriptions for projections. You either end up fighting your database to maintain these invariants, or you accept a solution that wasn't designed with performance as a first-class concern.
SierraDB takes inspiration from Cassandra in regards to its scalability and partitioning, and AxonServer with its segmented append-only file structure - but reimagined in Rust for predictable performance and without the overhead of garbage collection.
Why SierraDB?
SierraDB addresses specific gaps in the event sourcing database landscape.
Rust provides predictable performance without garbage collection pauses - important when you need consistent latencies. Memory safety without runtime overhead means fewer surprises in production.
Using RESP3 means no custom drivers needed. Every language with a Redis client works immediately. You can even use redis-cli to explore your event store, making debugging and development straightforward.
The partition model supports horizontal scaling from the start. Begin with a single node and 32 partitions, scale to hundreds of nodes with 1024+ partitions. Replication and consensus aren't bolted-on features - they're core to the design.
Subscriptions are built into the protocol. Event sourcing isn't just about storing events - projections and event handlers need to stay in sync with the event log. SierraDB can stream events from any point in history, making this simple to implement.
Core Architecture: Partitions, Buckets, and Segments
SierraDB stores events into a fixed number of logical partitions within a cluster. This is decided when initialising your database, and may be set to 32 partitions for a single node setup, or 1024 for a setup with many nodes.
The number of partitions is crucial: each partition processes writes sequentially, giving us gapless monotonic sequence numbers. This means your partition count is effectively your maximum concurrency for writes - 32 partitions means up to 32 concurrent write streams. But more isn't always better. Event handlers need to track their position per partition, so too many partitions adds overhead for consumers. It's a balance between write throughput and consumer complexity.
Each node in a cluster stores events in append-only files belonging to buckets. The number of buckets is typically divisible by the number of partitions. For example, 32 partitions, and 4 buckets = each bucket stores 8 partitions. Each bucket writes 256MB segment files, rolling over to a new one once the previous fills. This gives us immutable data, allowing segments to be indexed once and cached forever, without the file size growing indefinitely.
The data directory of a node might look like this:
data/
buckets/
00000/
segments/
0000000000/
data.evts # Raw append-only event data
index.eidx # Event ID index (lookup event by ID)
partition.pidx # Partition index (scan events by partition ID)
stream.sidx # Stream index (scan events by stream ID)
0000000001/...
00001/...
00002/...
00003/...
The Version Guarantee: Getting Ordering Right
Event sourcing has one non-negotiable requirement: stream version numbers. Every event within a stream gets a monotonically incrementing number starting from 0, with no gaps. Version 0, 1, 2, 3 - never 0, 1, 3, 4.
This guarantee enables optimistic locking: when appending events, you specify the expected version. If another process wrote to that stream since you last read it, the append fails and you retry. It's non-blocking concurrency control, but it requires absolute certainty that missing a version means a conflict, not data loss. A gap in versions would be catastrophic - it would mean lost events.
Why not use a global sequence number? Some databases do this, but it becomes a bottleneck in distributed systems. Every write would need to coordinate through a single counter. SierraDB takes a different approach: each partition has its own monotonic, gapless sequence number. Partitions progress independently, giving you the ordering guarantees you need without the coordination overhead. Event handlers simply track which sequence they've processed per partition, rather than maintaining a single global position. This also enables parallel event handling by consumers.
Cross-stream transactions through shared partition keys. Streams in SierraDB are mapped to partitions using a partition key - by default, a UUIDv5 derived from the stream ID. But here's the key insight: you can give multiple streams the same partition key. When a user-123 stream and an account-456 stream share a partition key, they're guaranteed to live in the same partition. This means you can atomically append events to both streams in a single transaction, without distributed coordination. The partition key acts as a correlation ID, letting you group related streams that need transactional consistency.
Distributed Consensus Without the Complexity
Running a cluster of nodes in SierraDB gives us redundancy through replication. Each partition is replicated across multiple nodes based on your replication factor - if you set it to 3, every event lives on 3 different nodes. All writes require majority quorum (2 out of 3 nodes majority agreement) before being considered successful, ensuring durability even if a node fails.
Here's where SierraDB diverges from traditional distributed databases: reads don't require quorum. Instead, each event stores a confirmation count in its metadata. When a write achieves quorum, a background process broadcasts this confirmation to all replicas, updating their local confirmation counts. This means any single node can serve consistent reads without network round-trips - a massive performance win.
But distributed systems are messy. Writes can complete out of order, network messages can be delayed, and confirmations might arrive in any sequence. Imagine partition sequence 100 is confirmed, but 99 is still pending - reading up to 100 would create a gap, breaking our guarantee.
This is where the watermark system comes in. Each partition tracks its "highest continuously confirmed sequence" - essentially, how far we can read without hitting a gap. If sequences 1-98 and 100-102 are confirmed, the watermark stays at 98. Once 99 confirms, it jumps to 102. Readers only see events up to the watermark, guaranteeing they always get a consistent, gap-free view of the partition.
Sequences: 96 97 98 | 99 100 101 102
State 1: ✓ ✓ ✓ | ? ✓ ✓ ✓ ← Watermark at 98
└─ gap prevents reading beyond 98
State 2: ✓ ✓ ✓ ✓ ✓ ✓ ✓ ← Watermark at 102
└─ continuous, can read all
For leadership and coordination, SierraDB uses term-based consensus inspired by Raft. Each partition has a leader node that coordinates writes, with automatic failover if the leader becomes unavailable. But unlike full Raft, we use deterministic leader selection based on the cluster topology - no expensive elections needed.
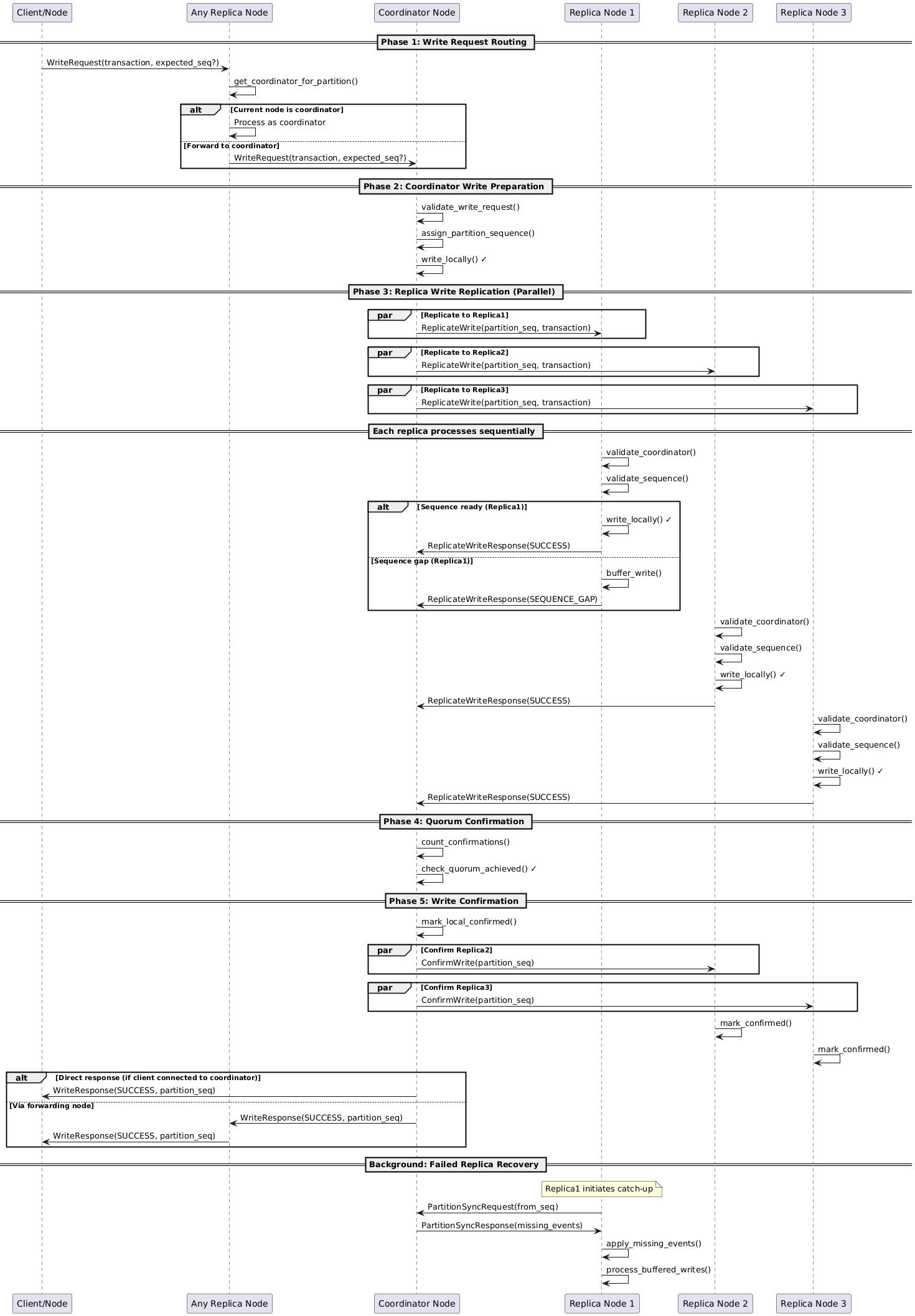
Here's a detailed diagram of the three-phase write protocol within SierraDB.
Standing on Giants' Shoulders
The chosen protocol for communicating with the database is Redis' RESP3. It's modern, simple, and most importantly - battle-tested. Every language has a Redis client, which means SierraDB works out of the box with existing libraries. No custom drivers needed. You can even use redis-cli to explore your event store, making debugging and development remarkably straightforward.
For inter-node communication, SierraDB uses libp2p - the same networking stack that powers IPFS and other distributed systems. It handles the complexity of peer discovery, connection management, and provides gossip protocol for topology management. Nodes can find each other, share cluster state, and route messages without requiring static configuration or service discovery.
The networking layer is built with Kameo, an actor framework I wrote for building fault-tolerant distributed systems in Rust. Actors provide isolated units of computation that communicate through message passing - perfect for handling concurrent operations in a distributed database. Each partition leader, replication coordinator, and background process runs as a supervised actor. If one crashes, it's automatically restarted without affecting the rest of the system. Kameo itself is built on libp2p, so the entire networking stack shares the same foundation.
These aren't arbitrary choices. RESP3 gives us immediate ecosystem compatibility. libp2p provides production-proven p2p networking. And actors give us fault isolation and supervision trees that make the system resilient to partial failures - critical properties for a database that needs to keep running when things go wrong.
Making It Usable
Getting a database to a stage where it's useful for others takes far more work than building a proof-of-concept. With RESP3 being used for commands, names had to be chosen which don't conflict with existing Redis commands, which is why all SierraDB commands are prefixed with E (EAPPEND, ESCAN, ESUB, etc).
Since this database is purpose built for event sourcing, first-class support for subscriptions was a priority. Clients can subscribe to all or specific partitions, starting from specific partition sequences, and SierraDB streams all historical events from the specified sequences, plus any new events appended afterward. This makes building projections and event handlers straightforward - no polling needed, no complex catch-up logic.
For Rust applications, kameo_es provides traits and types for defining aggregates and executing commands that persist to SierraDB - handling much of the domain modeling boilerplate.
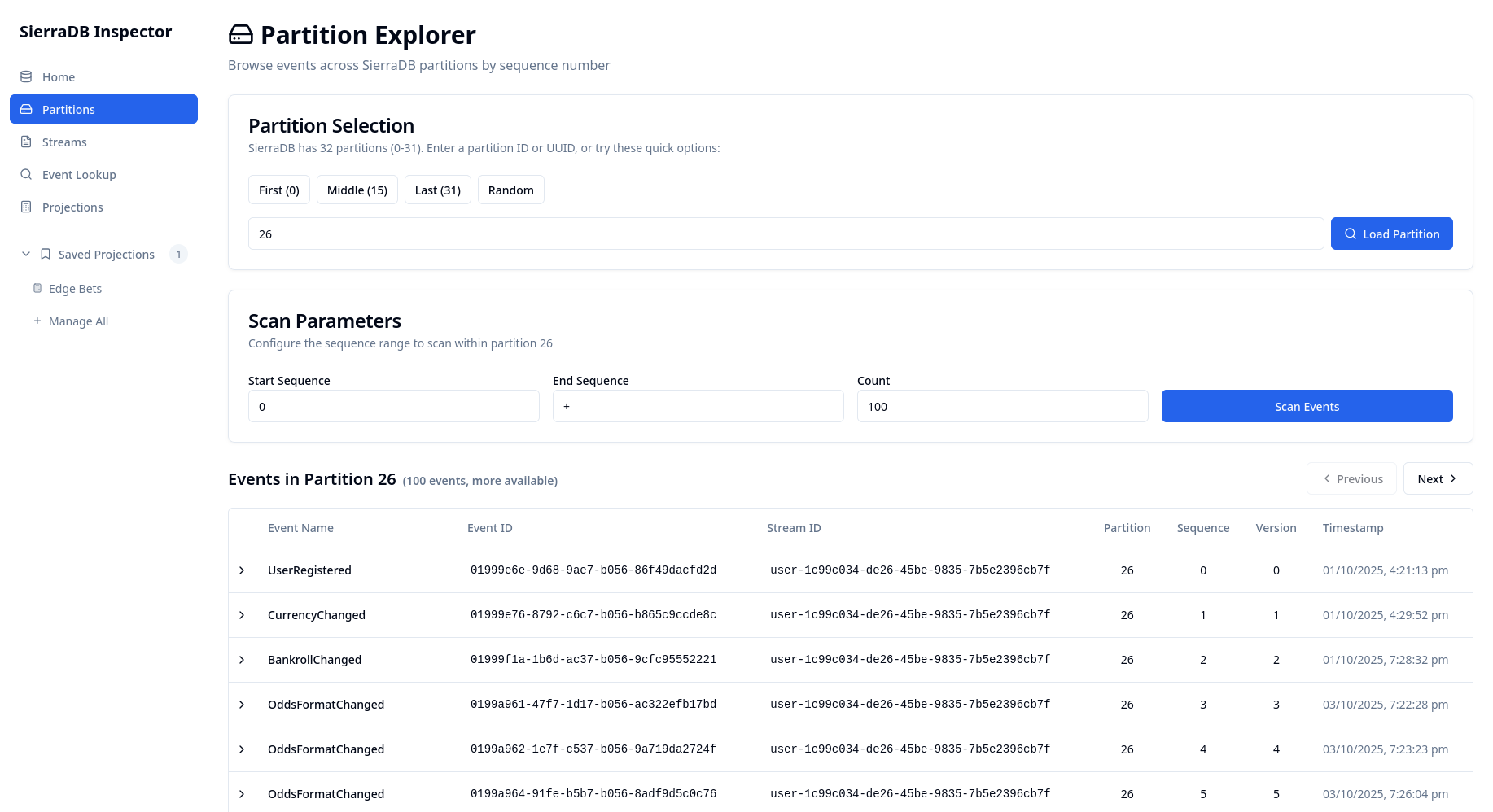
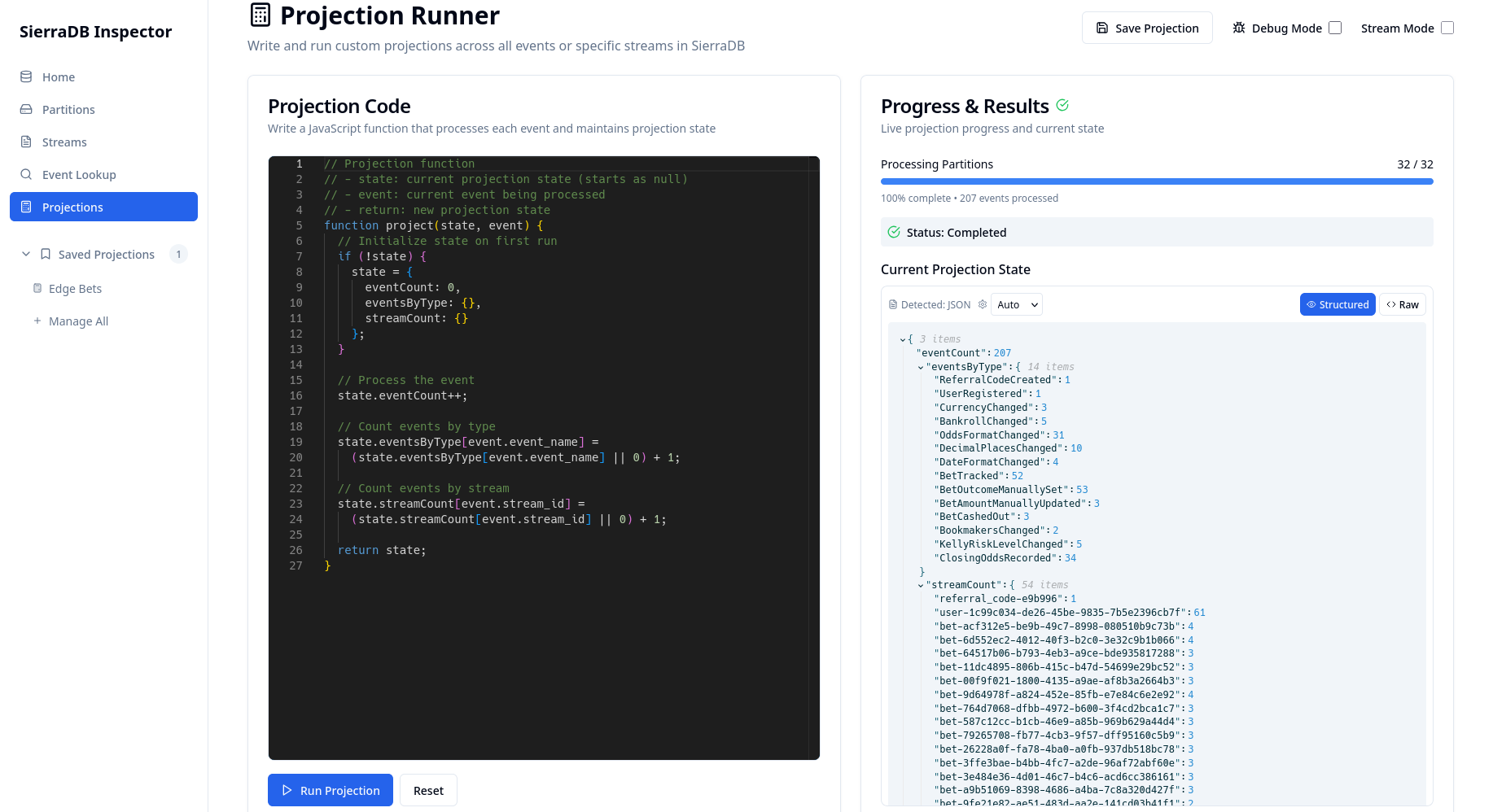
Database observability is crucial, especially for event sourcing where one of the huge benefits is seeing why events occurred. For this, SierraDB Inspector was built - a web interface for exploring events and running projections with JavaScript. Being able to quickly query and visualize your event streams makes debugging significantly easier.
Screenshots of SierraDB Inspector web interface.
Finally, getting started should be frictionless. Docker images are available on DockerHub, with one-liners to get up and running.
Current State, Lessons Learned, and What's Next
SierraDB runs stably under long-running stress tests, with major corruption issues ironed out. The core architecture — partitions, streams, subscriptions, RESP3 — feels right and stable. While performance still has room to grow, the foundation is solid. The design decisions are the result of years of trial and error from different approaches to building event sourcing systems.
My goal is to evolve SierraDB into a production-ready, open-source event store that scales with modern workloads — and I’d love help getting there. Docs and tests are still early, so contributions are incredibly welcome.
Try It Out
docker run -p 9090:9090 tqwewe/sierradb
redis-cli -p 9090
> EAPPEND user-123 UserCreated '{"name": "Alice"}'
> ESCAN user-123 - +